This comment/ essay by rgbatduke on WUWT is well worth reading and digesting.
“this is a point that is stunningly ignored — there are a lot of different models out there, all supposedly built on top of physics, and yet no two of them give anywhere near the same results!”
A professional taking amateurs to task!
(Note! See also his follow-up comments here and here. rgbatduke would seem to be Professor R G Brown of Duke University?)
rgbatduke says:
Saying that we need to wait for a certain interval in order to conclude that “the models are wrong” is dangerous and incorrect for two reasons. First — and this is a point that is stunningly ignored — there are a lot of different models out there, all supposedly built on top of physics, and yet no two of them give anywhere near the same results!
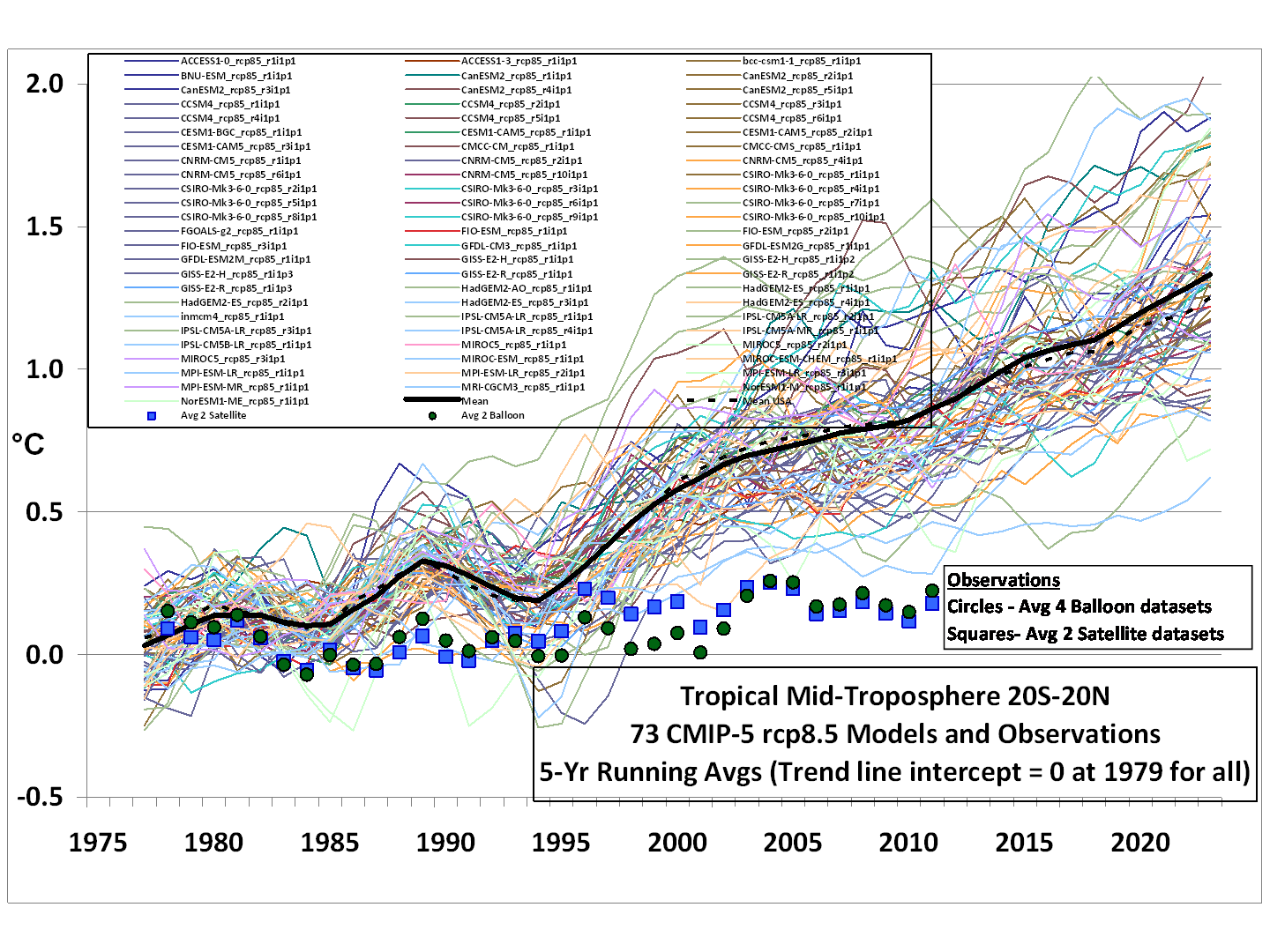
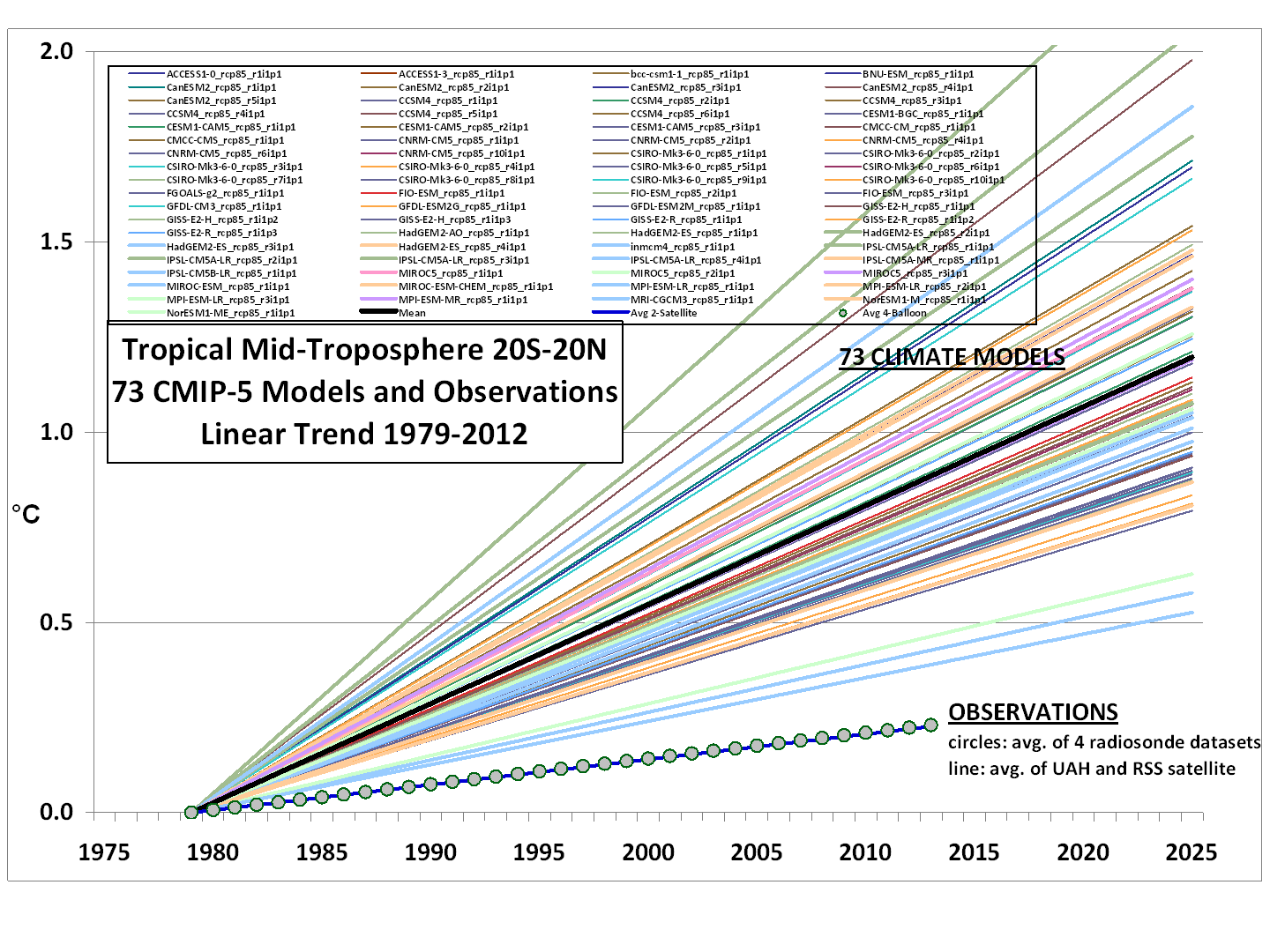
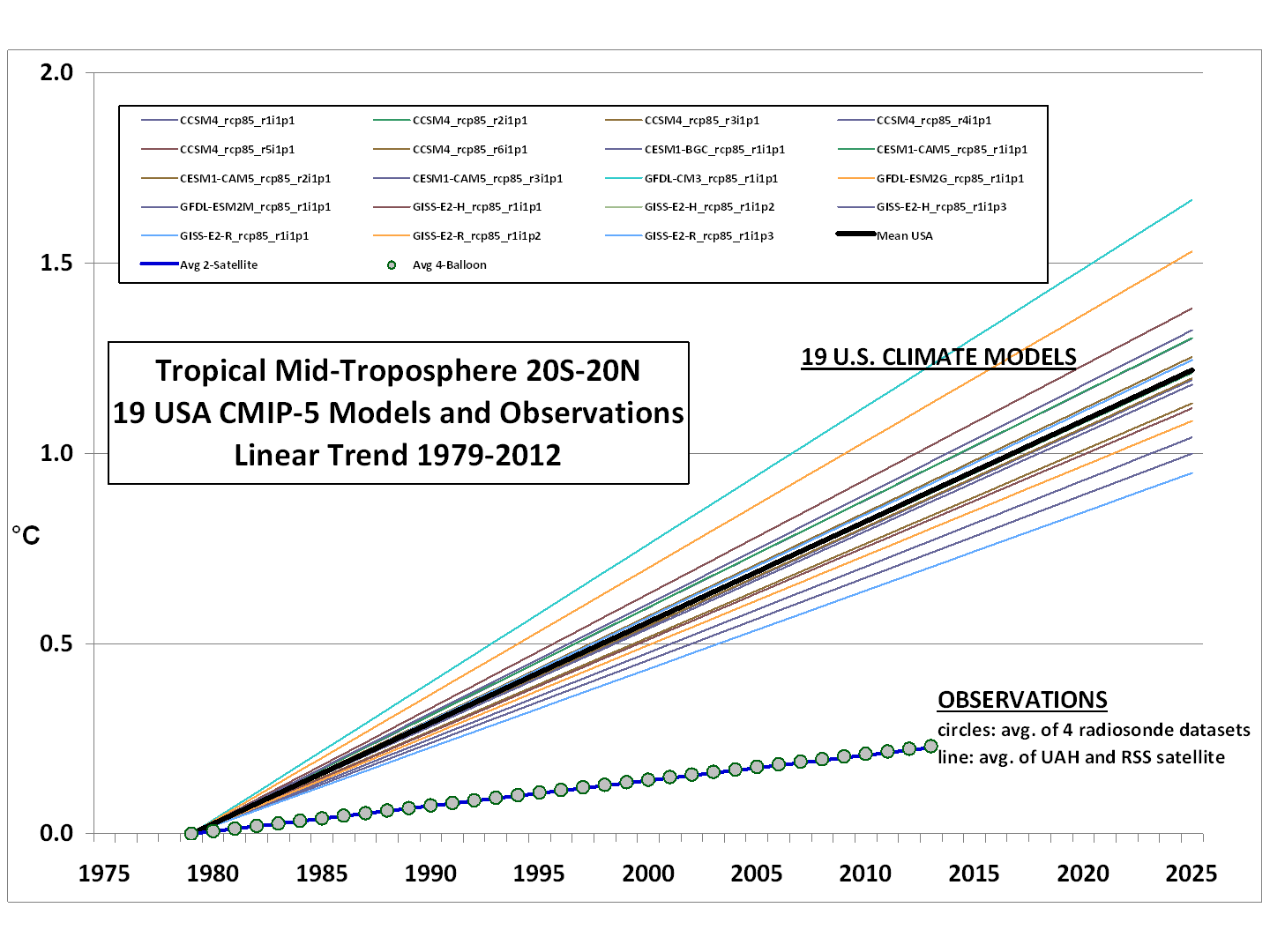
This is reflected in the graphs Monckton publishes above, where the AR5 trend line is the average over all of these models and in spite of the number of contributors the variance of the models is huge. It is also clearly evident if one publishes a “spaghetti graph” of the individual model projections (as Roy Spencer recently did in another thread) — it looks like the frayed end of a rope, not like a coherent spread around some physics supported result.
Note the implicit swindle in this graph — by forming a mean and standard deviation over model projections and then using the mean as a “most likely” projection and the variance as representative of the range of the error, one is treating the differences between the models as if they are uncorrelated random variates causing >deviation around a true mean!.
Say what?
This is such a horrendous abuse of statistics that it is difficult to know how to begin to address it. One simply wishes to bitch-slap whoever it was that assembled the graph and ensure that they never work or publish in the field of science or statistics ever again. One cannot generate an ensemble of independent and identically distributed models that have different code. One might, possibly, generate a single model that generates an ensemble of predictions by using uniform deviates (random numbers) to seed
“noise” (representing uncertainty) in the inputs.What I’m trying to say is that the variance and mean of the “ensemble” of models is completely meaningless, statistically because the inputs do not possess the most basic properties required for a meaningful interpretation. They are not independent, their differences are not based on a random distribution of errors, there is no reason whatsoever to believe that the errors or differences are unbiased (given that the only way humans can generate unbiased anything is through the use of e.g. dice or other objectively random instruments).