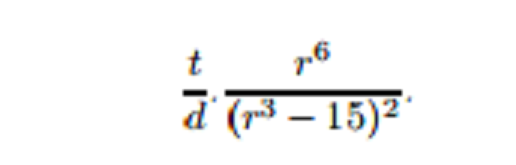I tend towards considering mathematics a language rather than a science. In fact mathematics is more like a family of languages each with a rigorous grammar. I like this quote:
R. L. E. Schwarzenberger, The Language of Geometry, in A Mathematical Spectrum Miscellany, Applied Probability Trust, 2000, p. 112:
My own attitude, which I share with many of my colleagues, is simply that mathematics is a language. Like English, or Latin, or Chinese, there are certain concepts for which mathematics is particularly well suited: it would be as foolish to attempt to write a love poem in the language of mathematics as to prove the Fundamental Theorem of Algebra using the English language.
Just as conventional languages enable culture and provide a tool for social communication, the various languages of mathematics, I think, enable science and provide a tool for scientific discourse. I take “science” here to be analaogous to a “culture”. To follow that thought then, just as science is embedded within a “larger” culture, so is mathematics embedded within conventional languages. This embedding shows up as the ability of a language to deal with numeracy and numerical concepts.
And that means then the value judgement of what is “primitive” when applied to language can depend upon the extent to which mathematics and therefore numeracy is embedded within that language.
GeoCurrents examines numeracy embedded within languages:
According to a recent article by Mike Vuolo in Slate.com, Pirahã is among “only a few documented cases” of languages that almost completely lack of numbers. Dan Everett, a renowned expert in the Pirahã language, further claims that the lack of numeracy is just one of many linguistic deficiencies of this language, which he relates to gaps in the Pirahã culture. …..
The various types of number systems are considered in the WALS.info article on Numeral Bases, written by Bernard Comrie. Of the 196 languages in the sample, 88% can handle an infinite set of numerals. To do so, languages use some arithmetic base to construct numeral expressions. According to Comrie, “we live in a decimal world”: two thirds of the world’s languages use base 10 and such languages are spoken “in nearly every part of the world”. English, Russian, and Mandarin are three examples of such languages. …..
Around 20% of the world’s languages use either purely vigesimal (or base 20) or a hybrid vigesimal-decimal system. In a purely vigesimal system, the base is consistently 20, yielding the general formula for constructing numerals as x20 + y. For example, in Diola-Fogny, a Niger-Congo language spoken in Senegal, 51 is expressed as bukan ku-gaba di uɲɛn di b-əkɔn ‘two twenties and eleven’. Other languages with a purely vigesimal system include Arawak spoken in Suriname, Chukchi spoken in the Russian Far East, Yimas in Papua New Guinea, and Tamang in Nepal. In a hybrid vigesimal-decimal system, numbers up to 99 use base 20, but the system then shifts to being decimal for the expression of the hundreds, so that one ends up with expressions of the type x100 + y20 + z. A good example of such a system is Basque, where 256 is expressed as berr-eun eta berr-ogei-ta-hama-sei ‘two hundred and two-twenty-and-ten-six’. Other hybrid vigesimal-decimal systems are found in Abkhaz in the Caucasus, Burushaski in northern Pakistan, Fulfulde in West Africa, Jakaltek in Guatemala, and Greenlandic. In a few mostly decimal languages, moreover, a small proportion of the overall numerical system is vigesimal. In French, for example, numerals in the range 80-99 have a vigesimal structure: 97 is thus expressed as quatre-vingt-dix-sept ‘four-twenty-ten-seven’. Only five languages in the WALS sample use a base that is neither 10 nor 20. For instance, Ekari, a Trans-New Guinean language spoken in Indonesian Papua uses base of 60, as did the ancient Near Eastern language Sumerian, which has bequeathed to us our system of counting seconds and minutes. Besides Ekari, non-10-non-20-base languages include Embera Chami in Colombia, Ngiti in Democratic Republic of Congo, Supyire in Mali, and Tommo So in Mali. ……
Going back to the various types of counting, some languages use a restricted system that does not effectively go above around 20, and some languages are even more limited, as is the case in Pirahã. The WALS sample contains 20 such languages, all but one of which are spoken in either Australia, highland New Guinea, or Amazonia. The one such language found outside these areas is !Xóõ, a Khoisan language spoken in Botswana. …….

Counting monkey?
In some societies in the ancient past, numeracy did not contribute significantly to survival as probably with isolated tribes like the Pirahã. But in most human societies, numeracy was of significant benefit especially for cooperation between different bands of humans. I suspect that it was the need for social cooperation which fed the need for communication within a tribe and among tribes, which in turn was the spur to the development of language, perhaps over 100,000 years ago. What instigated the need to count is in the realm of speculation. The need for a calendar would only have developed with the development of agriculture. But the need for counting herds probably came earlier in a semi-nomadic phase. Even earlier than that would have come the need to trade with other hunter gatherer groups and that probably gave rise to counting 50,000 years ago or even earlier. The tribes who learned to trade and developed the ability and concepts of trading were probably the tribes that had the best prospects of surviving while moving from one territory to another. It could be that the ability to trade was an indicator of how far a group could move.
And so I am inclined to think that numeracy in language became a critical factor which 30,000 to 50,000 years ago determined the groups which survived and prospered. It may well be that it is these tribes which developed numbers, and learned to count, and learned to trade that eventually populated most of the globe. It may be a little far-fetched but not impossible that numeracy in language may have been one of the features distinguishing Anatomically Modern Humans from Neanderthals. Even though the Neanderthals had larger brains and that we are all Neanderthals to some extent!